SEO Workshop: Werking Zoekmachine
De zoekmachine is een soort “Gatekeeper” van je website.

Zij bepaalt hoe goed je gevonden wordt en wie je website zal ontdekken. Immers, de zoekmachine is veel handiger voor gebruikers dan IP adressen, domeinnamen en indexeringsprogramma’s zoals Archie!
De zoekmachine werkt in drie stappen
1) Crawling
2) Indexeren
3) Ranking
1. Crawling
Het internet (world wide web) bestaat uit een gigantische hoeveelheid webpagina’s die voornamelijk door hyperlinks aan elkaar gekoppeld zijn.
Elke link is een “draad” waarlangs de spider naar andere webpagina’s kan crawlen.

Zoekmachines hebben teams van Crawler-bots (oftwel Spiders) die doorheen het web navigeren door URLs te volgen. Die crawler-bots zijn computerprogramma’s die automatisch webpagina’s scannen en lezen.
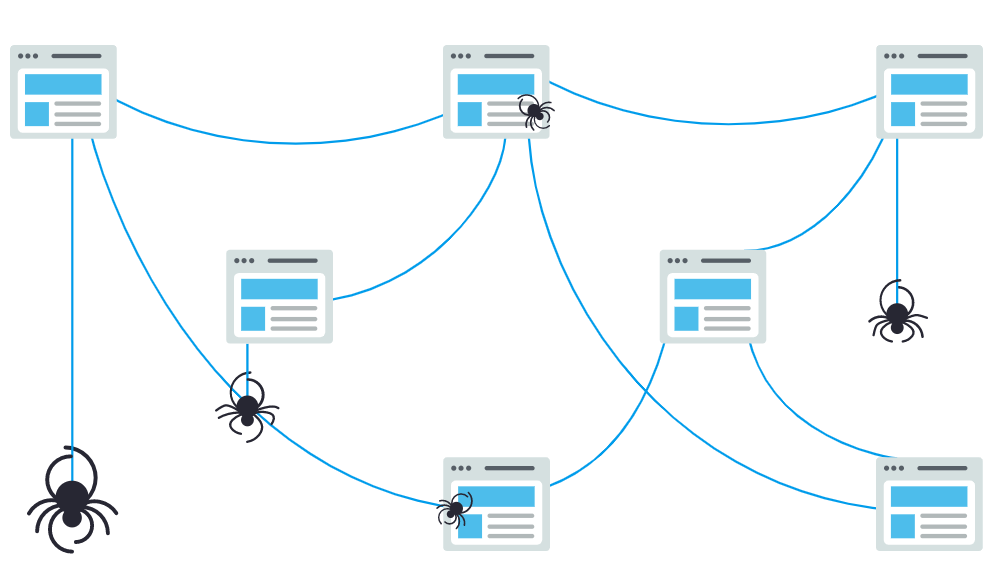
Voorbeeld van een crawler bot
- Googlebot: Dit is de crawler bot van Google. Hij is verantwoordelijk voor het indexeren van miljarden webpagina’s.
- Bingbot: De crawler bot van Bing, de zoekmachine van Microsoft.
Bemerking inzake Crawlers
We kunnen de crawler-bots helpen via een sitemap.xml. We kunnen pagina’s blokkeren via een robots.txt.
Beide onderwerpen bespreken we later in meer detail.
2. Index: Website indexeren
De content die door Crawlers/Spiders gevonden wordt, wordt in de index opgeslagen. De index is de databank van Google waaruit de zoekresultaten worden gehaald.
Wanneer spiders webpagina’s vinden worden deze toegevoegd aan de index waardoor ze in de SERP’s kunnen verschijnen.
De inhoud van je website wordt geanalyseerd door de crawler zodat deze kan beoordelen of je een goede “match” bent voor bepaalde zoekopdrachten.
Bemerk dat we enkel de belangrijkste pagina’s willen indexeren (niet alle categorieën en archiefpagina’s) om een zo goed mogelijke ranking te verkrijgen.
Waarom zou dit kunnen zijn?

3. Ranking: volgorde SERP’s bepalen
Het doel van de zoekmachine is om content aan te bieden die het best aansluit op de vraag van de gebruiker.
Als jij niet tevreden bent van de resultaten die Google jou geeft, ga je misschien een andere zoekmachine gebruiken…
De geïndexeerde resultaten wil Google dus in een relevante volgorde tonen (ranken).
Hierbij gaat de zoekmachine
- interpreteren wat de intentie is van de zoekopdrachtgever
- gerelateerde pagina’s identificeren
- pagina’s ranken om de meest relevante antwoorden eerst aan te bieden
Voor ranking worden (geheime) algoritmes gebruikt. Hier spreken we van Search Ranking Factors (SRFs) die elk een numeriek gewicht krijgen en die samen bepalen welke resultaten eerst moeten komen.
Tegenwoordig wordt er ook sterk rekening gehouden met ‘Lokale SEO‘ om het zoekresultaat af te stemmen op de gebruiker.
Wat zou dit kunnen zijn? Kan je een voorbeeld geven?

Click Through Rate (CTR)
Het is belangrijk om hoog te ranken in de SERP’s. Hoe hoger we staan hoe meer zichtbaarheid, hoe meer bezoekers en dus meer inkomsten.
Een click-through rate (CTR), ofwel de doorklikratio, geeft aan hoeveel procent van de mensen die een zoekresultaat zien, er ook daadwerkelijk op klikken.
De eerste paginarank heeft een gemiddelde CTR van 28.5%.

Featured Snippets kunnen hier ook een grote meerwaarde bieden aangezien deze 23.3% CTR hebben.
Wat zijn Featured Snippets?
Je zoekt iets in Google en Google kan jou een direct antwoord geven op jouw gestelde vraag. Dat antwoord is een featured snippet.
Zoals deze featured snippet een antwoord geeft op de vraag ‘wat is een featured snippet?’ ;-):

Lees hier meer over de Click Through Rates.