PBi_2_Data binnentrekken en klaarmaken
We hebben daarnet gezien dat er ongelooflijk veel data bronnen gebruikt kunnen worden binnen PowerBI.
Je krijgt deze ook allemaal te zien als je ‘Get Data‘ doet als de applicatie geopend is.
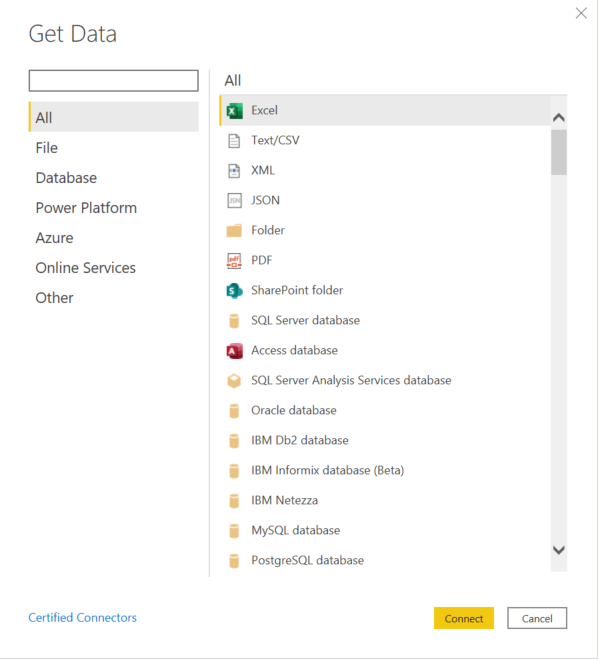
Het gebeurt zelden, maar als jouw databron niet tussen de lijst zou staan, kan je altijd gaan via de generieke ODBC (Open DB Connector) om jouw databron te selecteren.
Het is ook mogelijk om binnen een project meerdere databronnen te gebruiken en te laten samenwerken in één datamodel.
Zo kan je bijvoorbeeld één bestand selecteren van de SQL Server database en een andere bestand van Excel of Sharepoint en zo verder.
Afhankelijk van de databron die je gebruikt gaat PowerBI jou verschillende vragen stellen.
Bijvoorbeeld SQL gaat jou de locatie en de naam van de server vragen, jouw inloggegevens en zo meer.
Wij gaan voor het gemak van deze workshop opnieuw starten met een Excel-file.
- Selecteer ‘Excel‘ en klik op ‘Connect‘.
- Browse naar de plaats waar je jouw files opgeslagen hebt.
- Selecteer in eerste instantie de ‘AdventureWorks_Database‘.
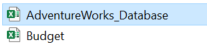
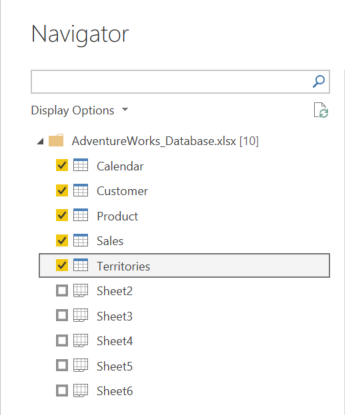
PowerBI analyseert de file, waar die ook vandaan komt, kijkt wat er in aanwezig is en opent de ‘Navigator‘ met alle aanwezige entiteiten.
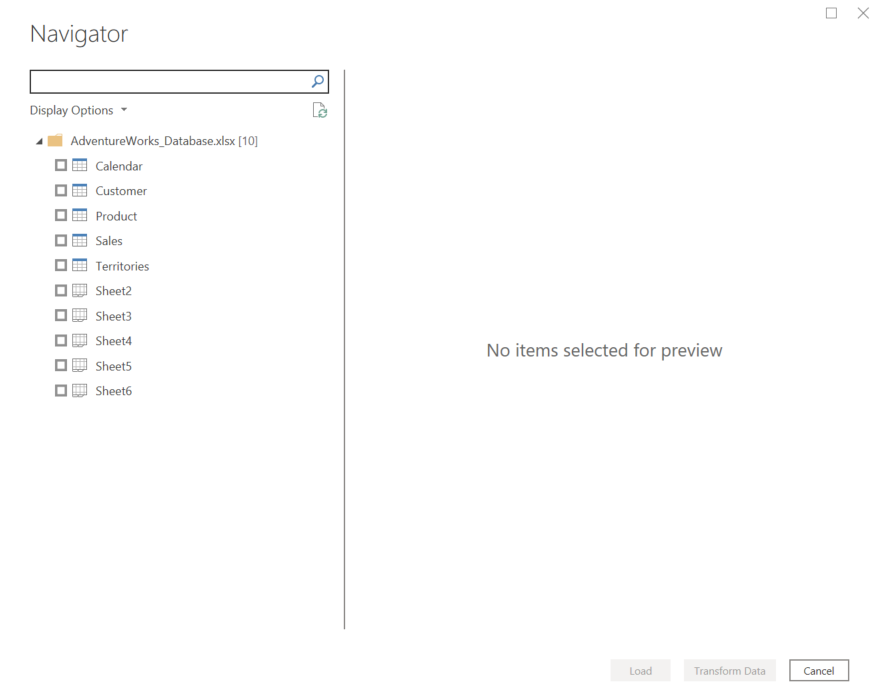
Nu, zoals je zal zien in die navigator, zijn er zowel benoemde tabellen als onbenoemde tabellen aanwezig. Dit gebeurt soms bij Excel-bestanden en dit kan behoorlijk verwarrend zijn.
Maar als je kijkt naar de inhoud van bijvoorbeeld Sheet2, dan zie je dat die dezelfde is als de inhoud van de tabel ‘Calendar’.
Sheet3 is identiek aan de tabel ‘Customer’.
Sheet4 komt overeen met de tabel ‘Product’ en zo verder…
Als in het Excel-bestand (onder Tabelontwerp) de tabel een naam gekregen heeft, zullen zowel die naam als de Sheet opgenomen worden in de navigator van PowerBI.
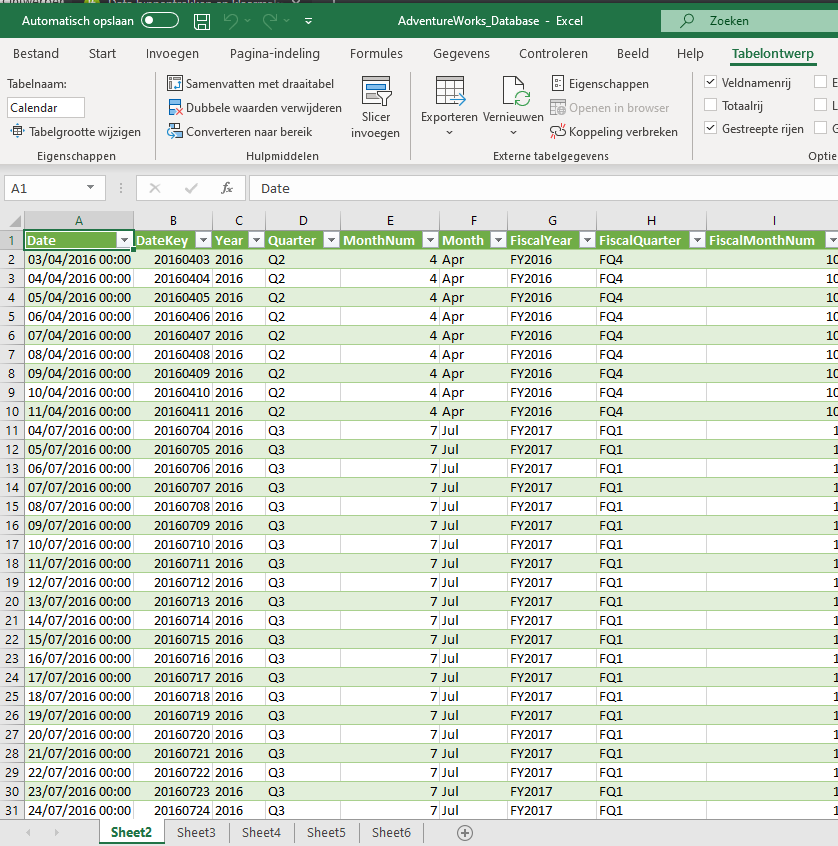
In onderstaand voorbeeld zie je hoe de Tabelnaam van Sheet2 ‘Calendar‘ is.
Wij kiezen in onze navigator de benoemde tabellen.
- Selecteer de 5 benoemde tabellen. De anderen hebben we niet nodig.
- Klik op ‘Laden‘ (Load)
PowerBI verbindt met de bron, welke dat ook is, en maakt een kopie van die dataset.
De dataset met de verschillende tabellen wordt zichtbaar in ons ‘Fields’-venster aan de rechterzijde van onze applicatie…
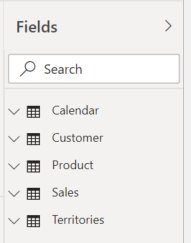
… maar ons scherm is nog steeds leeg. We zitten immers in de visualisatie-tab aan de linker kant.

Het tweede pictogram hebben we ook al gezien. Dit is de tab waarin we een zicht krijgen op onze data.

Door één van de tabellen te selecteren in het ‘Velden’-venster en naar ons ‘Datazicht‘ te gaan kunnen we zien waaruit de tabel precies is opgebouwd.

We gaan dit PowerBI-bestand nu opslaan en even kijken naar de bestandsgrootte…
Je kan hiervoor gaan via het ‘File’-menu of via het pictrogram van de diskette.

Ik bewaar mijn document in dezelfde folder als mijn oorspronkelijke Excel-bestanden.
De data hoeven niet in dezelfde folder te zitten als het PowerBI-bestand, maar ik zet hem hier om jullie iets te tonen… Is er iets dat jullie opvalt in onderstaande afbeelding?

Zoals je ziet is het PowerBI-bestand veel kleiner dan het originele Excel-werkblad, wat behoorlijk verbazend is als je weet dat Excel de bestanden al in een gecomprimeerd formaat opslaat.
PowerBI is verbazingwekkend wat het comprimeren van data betreft!
Dit maakt het voor PowerBi mogelijk om honderden miljoenen rijen aan te kunnen.
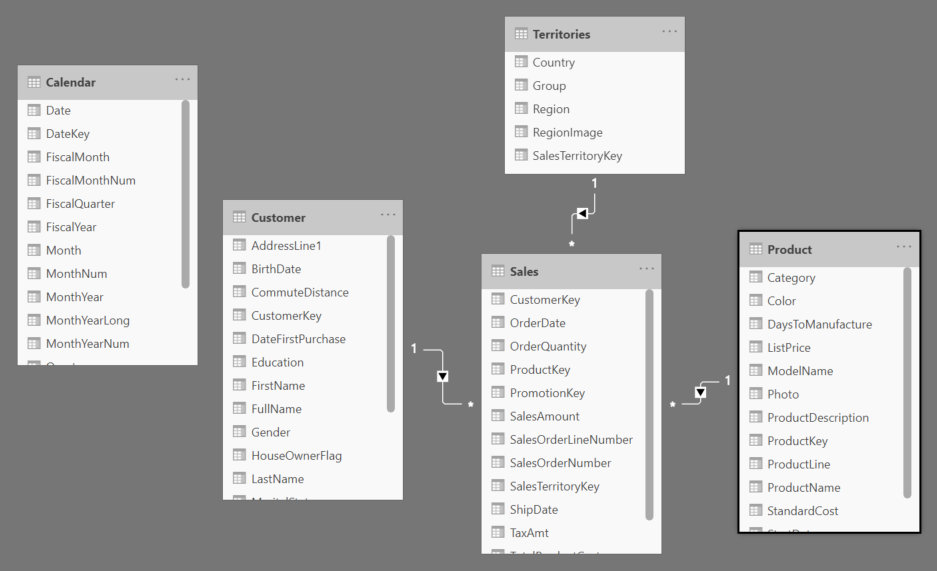
En tenslotte hebben we nog onze model- of relatietab.

Dit geeft ons zicht op de verschillende tabellen, hun velden en de relaties die PowerBI automatisch gemaakt heeft. We gaan hier zo meteen nog op terug komen.
De dataset die we hier hebben binnengetrokken was extreem zuiver. We hebben hier niets aan hoeven doen, maar zoals we gezien hebben in dag 1 van de workshop is dat niet altijd het geval. Beter gezegd: we hebben vaker te maken met ‘rommelige’ data in plaats van goed opgebouwde zuivere datasets. De 2de file die in onze map ‘DATA’ zit, is daar een goed voorbeeld van.
Als we de file open doen in Excel, ziet die er zo uit:
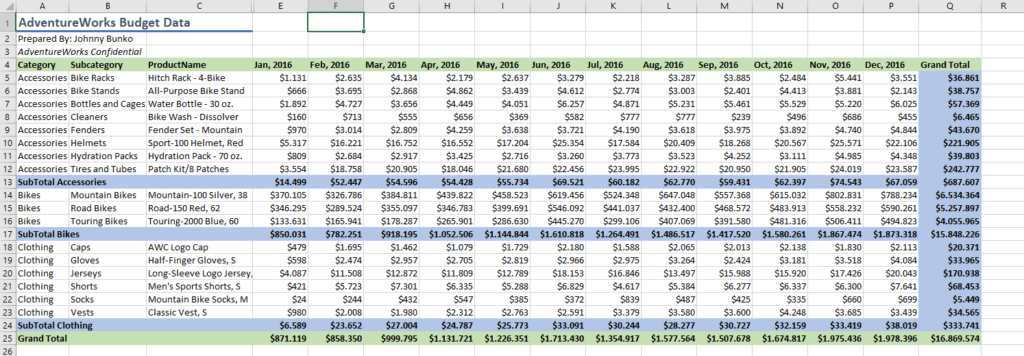
Wij, mensen, vinden deze tabel misschien op het eerste zicht niet rommelig, maar de kleuren bijvoorbeeld hebben voor de computer, of beter voor PowerBI, weinig betekenis.
PowerBI heeft ook geen boodschap aan de bovenste rijen die enkel aanwezig zijn voor ons, mensen, om bijkomende informatie te krijgen.
We zien hier ook de maanden van 2016 verspreid over verschillende kolommen wat voor ons overzichtelijk is maar onhandig om ons datamodel op te bouwen en ‘best practice’ is het al zeker niet…
Dan is de kolom ‘Grand Total‘ eigenlijk overbodig want de nodige gegevens staan reeds in de tabel en kunnen gemakkelijk door PowerBI berekend worden.
Er zijn de subtotalen op verschillende plaatsen die we niet echt nodig hebben…